Fedora accounts system provides OpenID authentication. If you are using python-fedora to do authentication in your webapp, you already know what I am talking about. I wanted to do the same, but from a webservice written in golang. I found a few working openid solutions in golang but none of them provides the sreg and other extensions which FAS supports.
I pushed patched openid.go in my github which by default supports all the extensions for FAS. We have an example which shows how to access the Verify function and the output. Now you can have FAS authentication if your app too :)
id, err := openid.Verify(
fullUrl,
discoveryCache, nonceStore)
You can read the part1 and part2.
It is a string literal which is in the first statement of a module, class or function. It becomes the __doc__ attribute of the object. It contains an explanation of that object (can be module, class or a function) does.
def foobar(a, b):
"Does foobar with a,b and returns some result"
You must have seen examples of docstrings when you started learning Python but may be you never paid enough attention to it. Now is a good time to start doing that. All the code you are writing will be used by someone (may be by you only) in future and docstrings will come into help. Remember the time when you use help command in the interpreter to learn more quickly?
>>> help(enumerate)
Help on class enumerate in module __builtin__:
class enumerate(object)
| enumerate(iterable[, start]) -> iterator for index, value of iterable
|
| Return an enumerate object. iterable must be another object that supports
| iteration. The enumerate object yields pairs containing a count (from
| start, which defaults to zero) and a value yielded by the iterable argument.
| enumerate is useful for obtaining an indexed list:
| (0, seq[0]), (1, seq[1]), (2, seq[2]), ...
|
| Methods defined here:
|
| __getattribute__(...)
| x.__getattribute__('name') <==> x.name
|
| __iter__(...)
| x.__iter__() <==> iter(x)
|
| next(...)
| x.next() -> the next value, or raise StopIteration
|
| ----------------------------------------------------------------------
| Data and other attributes defined here:
|
| __new__ = <built-in method __new__ of type object>
| T.__new__(S, ...) -> a new object with type S, a subtype of T
It actually shows the carefully written docstrings by the Python authors. Now put yourself in their shoes and try to imagine the developer who will be using your code in future.
We can have either one line or multiline docstring. If you have multiline docstring using “”” (triple quotes) then it is suggested that you have a blank line before the closing quotes. You should at least have the closing quotes on a new line.
We can also use the same docstring to create auto generated API in Sphinx , though that depends project to project.
Let us have a look into one method from python-fedora module
def people_by_key(self, key=u'username', search=u'*', fields=None):
'''Return a dict of people
:kwarg key: Key by this field. Valid values are 'id', 'username', or
'email'. Default is 'username'
:kwarg search: Pattern to match usernames against. Defaults to the
'*' wildcard which matches everyone.
:kwarg fields: Limit the data returned to a specific list of fields.
The default is to retrieve all fields.
Valid fields are:
* affiliation
* alias_enabled
* bugzilla_email
* certificate_serial
* comments
* country_code
* creation
* email
* emailtoken
* facsimile
* gpg_keyid
* group_roles
* human_name
* id
* internal_comments
* ircnick
* last_seen
* latitude
* locale
* longitude
* memberships
* old_password
* password
* password_changed
* passwordtoken
* postal_address
* privacy
* roles
* ssh_key
* status
* status_change
* telephone
* timezone
* unverified_email
* username
Note that for most users who access this data, many of these
fields will be set to None due to security or privacy settings.
:returns: a dict relating the key value to the fields.
.. versionchanged:: 0.3.21
Return a Bunch instead of a DictContainer
.. versionchanged:: 0.3.26
Fixed to return a list with both people who have signed the CLA
and have not
'''
Using :kwarg parametername: each of the keyword argument is documented. It uses :returns: to mark the returned object details. Here is one more example from kitchen module.
def isbytestring(obj):
'''Determine if obj is a byte :class:`str`
In python2 this is equivalent to isinstance(obj, str). In python3 it
checks whether the object is an instance of bytes or bytearray.
:arg obj: Object to test
:returns: True if the object is a byte :class:`str`. Otherwise, False.
.. versionadded:: Kitchen: 1.2.0, API kitchen.text 2.2.0
'''
if isinstance(obj, str):
return True
return False
Btw, never mix up between code comments and docstrings, you should never use double or triple quotes to write random comments inside your code. You should always use hashes (#) to make any comments inside your code. To know more about docstrings one should read PEP257.
We use reStructuredText as our primary markup syntax for all documentations. It is plaintext and you can use it for your docstrings too. Go through this quick presentation to start writing reStructuredText. later you can learn about all directives.
Btw, that presentation was also written using reStructuredText, you can read the source file and use rst2s5 command to create your own presentation.
If you are using vim or emacs then you can just continue using it. If you use sublime, you should also check out Restructured Text (RST) Snippets plugin.
So we saw benefits of having documentation in the last post . In this post I will go through another topic we discuss a lot, code comments or not!
Let us look into a more common thing first. Look at the handwriting below and think if you have to read some notes/answer sheet/ideas, which side of the text you want it to be like? Left or Right?

Text from left hand side, you can read and understand. What about the right hand side text? Do you really want to read a 10 page long document in that handwriting? Now use the same ideas into the code you read regularly. People read a piece of code a many times than you think. (Btw, the right hand side was my own handwriting few months back.)
If you can not read your code without comments that means you are surely doing it in a wrong way, it is just bad code. You can think about comments as the extra toppings on top of your regular pizza, but it can not become your regular pizza (i.e. your code). Think about a world where comments do not exist, you have to name your variables right, refactor the code till it becomes obvious so that others can read and understand. Remember the Zen of Python
Simple is better than complex.
Also remember that the comments are for human reader, they are not for the interpreters or compliers. There are many cases where a long comment will confuse the reader more than helping. This brings in another favorite quote.
to write good comments you have to be a good writer.
– Jeff Atwood
But you may still want to have comments for other reasons. Let us look into some of those cases.
Let us now look into a proper code comment example. Below are the lines from io.py in CPython.
# Declaring ABCs in C is tricky so we do it here.
# Method descriptions and default implementations are inherited from the C
# version however.
class IOBase(_io._IOBase, metaclass=abc.ABCMeta):
pass
Now you can clearly see that there is no easy of saying that ABCs are tricky through your code, so the authors chose two simple English statements to explain it all.
The last point to discuss is about having comments or name variables in your code in your mother tongue (other than English). Bad idea, you really don’t know the future. The next person who will read your code might be from another part of the world, English is the standard language for all of the programmers, try to follow the same path.
Please share your thoughts on the same as comments here or reply on twitter. In the next post I will look into docstrings in Python code.
Yes, it is the primary medium to communicate to you users. You may have an API service or an installable library or an application, but your documentation quality matters when you think about retaining old users and getting new one!
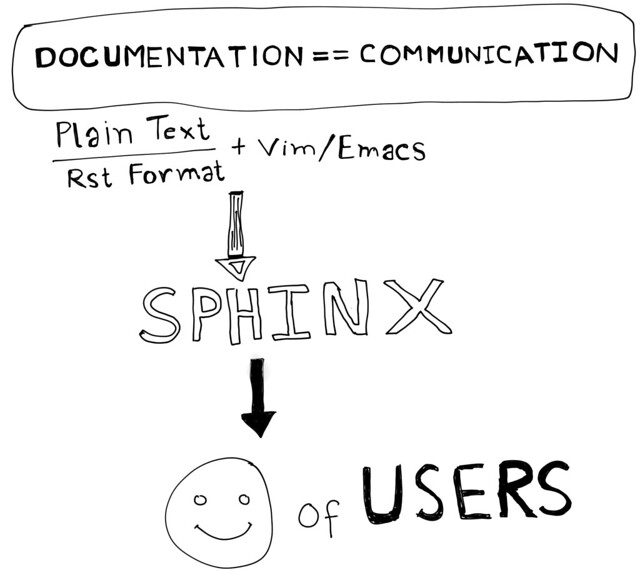
Above is an old sketchnote I did, happiness of the users matters most and it can only come with providing a superb documentation along with your application/API.
Documentation comes in different forms, for the users first thing is a quickstart docs, something which can tried within 5-10 minutes, then comes tutorials and how-to guides, which can vary from 30 minutes to couple of hours to complete. API documentation comes after that, mostly for your experienced users, in-depth details and examples should be part of it.
There are many projects who will not accept a patch without the necessary documentation changes along with it. If you look into projects like Django or Qt , you will understand why they have such big userbase. Along with the excellent product, they provided world class documentation. There is another point which these projects teach, who should write the initial documentation?
You read correct, not any new contributors but the developers themselves. As a developer, you already have better idea of the project and how it works, if you write the initial documentation that will help more for new contributors than them trying to find out how things work and then write the docs.
In next part I will discuss more on code comments.
Last week we had PyCon India 2013, in Bangalore. I went there on Thursday night and stayed at @rtnpro’s place, we planned this as I was being able to discuss few other projects with him and met my gsoc student and look into the progress so far.
Day 1 was the workshop day, we reached the venue early as usual. Got breakfast and started meeting all the old friends :) That is the added advantage of having a conference in Bangalore that we can meet all the friends at one single place. I attended Anand Pillai’s “Idiomatic Programming - Getting the best out of your Python code” workshop, it had some nice and not so common idioms to try out. I guess many people who attended that workshop was beginner even though it was marked for Intermediate.
After that in the same room I had my workshop “Document your code”. Started with a few lines on why documentation is the primary medium of communication and how it plays a significant role in your userbase, Then we went ahead and wrote documentation for a simple Python module. There were few people with Windows in their laptops and installing packages took some time for them. But at the end it went very well as everyone managed to create their documentation and they confessed that it was not that hard as they thought it would be. Sphinx is making the entry barrier very low for beginners. I also talked about why it is a good idea that the developers should write the primary documentation instead of anyone who is very new to the project.

dgplug had around 16 members present in this version of PyCon. Many students from this year’s summer training also turned up. At evening we all went out for dinner at a nearby place, sadly someone’s camera was stolen in this short trip in the bus to the dinning place :(
Morning started with bad rain, it took us 1.5 hours to go 3.5km distance! Somehow managed to reach the venue just before Jace’s keynote. He started his talk with one single line in a text editor.

You can watch the keynote here.
I spent rest of the day talking with people and writing more code :) There was a panel discussion on Python in education. At night we had speakers and volunteers dinner.
Day started with another amazing keynote from Kenneth Reitz.

We had a dgplug meeting and chose new coordinators, details will be on another post.
Anisha did an wonderful job in her talk, Let’s talk testing with Selenium. The room was full and many people said good things about the talk after they came out of it. Ramki also conducted an openspace in the style of TIP bof. I demoed basic usage of coverage there.
In the evening we had the AGM of PSSI and various points related to spreading Python in India was discussed there. Konark was chosen as vice-president of the society.
Writing this post as a note to myself. Many times we want to fetch records from MySQL row by row. We try to do that by the following code
import MySQLdb
conn = MySQLdb.connect(user="user", passwd="password", db="dbname")
cur = conn.cursor()
cur.execute("SELECT id, name FROM students")
row = cur.fetchone()
while row is not None:
print row[0], row[1]
row = cur.fetchone()
cur.close()
conn.close()
But remember that the default cursor fetches all data at once from the server, it does not matter that if you use fetchall or fetchone.
You have to use a different cursor which supports server side resultsets, like SSCursor or SSDictCursor.
import MySQLdb
import MySQLdb.cursors
conn = MySQLdb.connect(user="user", passwd="password", db="dbname",
cursorclass = MySQLdb.cursors.SSCursor)
cur = conn.cursor()
cur.execute("SELECT id, name FROM students")
row = cur.fetchone()
while row is not None:
print row[0], row[1]
row = cur.fetchone()
cur.close()
conn.close()
Python for you and me, my Python book got a new look and a new home.
When I started writing this book, I used Publican as it helped a lot to create a nice looking pdf and static html pages which I can easily put into web. But editing docbook xml was a pain and the tool itself keep breaking things.
So, this year decided to move to the book into a Sphinx based document. First I had to migrate the xml source files into reStructuredText format and then with little more manual editing, the book was ready to move. The primary git location also changed to github and it is also hosted in readthedocs.org for online view. Result ? I saw suddenly a number of patches started coming in from the students, almost everyone was being able to make any required changes. Pingou also added a guest chapter on Flask and we are slowly increasing the book’s content.
A pdf copy is also available.
Right now I am doing small small incremental changes, please feel free to send in patches or simple github pull requests :)
During this weekend in PyCon India I released Retask 0.4. You can install it from PyPi.
Retask is a python module to create and manage distributed task queue/job queue.
It uses Redis to create task queues. User can enqueue and dequeue tasks in the queues they manage. Each task can contain any JSON serializable python objects. We use JSON internally to store the tasks in the queues.
We are working on one C library and one for Go. With these one can enqueue tasks in from a system written in a different language and execute it in a worker with a different language.

After a 44 hours flight + airport travel, finally managed to reach to Charleston airport around 3pm, our own, awesome “Jared Smith” came down to pick me up. Went to the hotel for a quick shower and ran to the venue. My workshop named “Document your code” was supposed to start at 4pm and somehow managed to do so. There were very less number of people but it seems they loved the whole idea of using Sphinx as a documentation system. Dave Crossland wrote about his experience in his blog post. After workshop, I started meeting all the people whom I knew for the last 7-8 years over IRC and mailing list (it is a long list of names ).
I wanted to attend the other workshop “Get Go-ing” but it was in the same time of my workshop. I went to the room after I finished and had nice chat with Vincent Batts who kept showing me all the cool hacks he was doing. I also hope that we will start having our first few Go packages in Fedora due to his excellent effort.
Later in the evening we all went to after party.
Somehow managed to wake up around 5:30am in the morning and reached the venue on time with the whole Fedora Infrastructure team :)
The day started with “Luzbot keynote”, this was first time I saw a working 3D printer, exciting time in future :) Next I attended Arun’s “Fedora at Yahoo!” talk. He gave a very nice introduction of Fedora usage inside Yahoo! and what all technology parts they chose and why.
Next I had my own talk on Darkserver: Current and future roadmap Toshio and Pingou gave some nice suggestions, which I passed to my gsoc student, I hope he will be able to use them wisely. I also thank “Stephen Smoogen” for moving his talk into my day one time slot and allow me to present in his slot.
After having some nice lunch I spent the second half mostly talking with various people.
Once again another amazing keynote by Dave Crossland. Next I attended “Ambassadors Work in a A Region - Annual Planning” talk, discussed over the we work and last few issues we had. The discussion was very constructive.
Second half I spent in between few talks and hallway discussions.
After the morning GPG key signing, spent the day in Infrastructure Hackfest. Long discussions and design decisions were made. More details are in the corresponding mailing lists.
As a whole the event went very well, having less number of parallel tracks might help a bit more. Thanks to the whole organizing team and all contributors who made Flock 2013 a successful event.
Photos of the event can be found here.
I am personally very sad to see Fedora’s name in this announcement. As an Indian, the text on that page is too much offensive and not sure what Fedora has to do with that particular issue. I am not against anyone but the way Fedora’s brand name is being used in random things, I am not sure where all places I will see the brand Fedora in future.
